AI tools for LLM evaluation
Related Tools:
Airtrain
Airtrain is a no-code compute platform for Large Language Models (LLMs). It provides a user-friendly interface for fine-tuning, evaluating, and deploying custom AI models. Airtrain also offers a marketplace of pre-trained models that can be used for a variety of tasks, such as text generation, translation, and question answering.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.
micro1
micro1 is an AI recruitment tool that leverages human data produced by subject matter experts to help companies identify and hire top talent efficiently. The platform offers end-to-end post-training solutions, high-quality data for model training, pre-vetted AI trainers, and enterprise-grade LLM evaluations. With a focus on tech startups, staffing agencies, and enterprises, micro1 aims to streamline the recruitment process and save costs for businesses.
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.
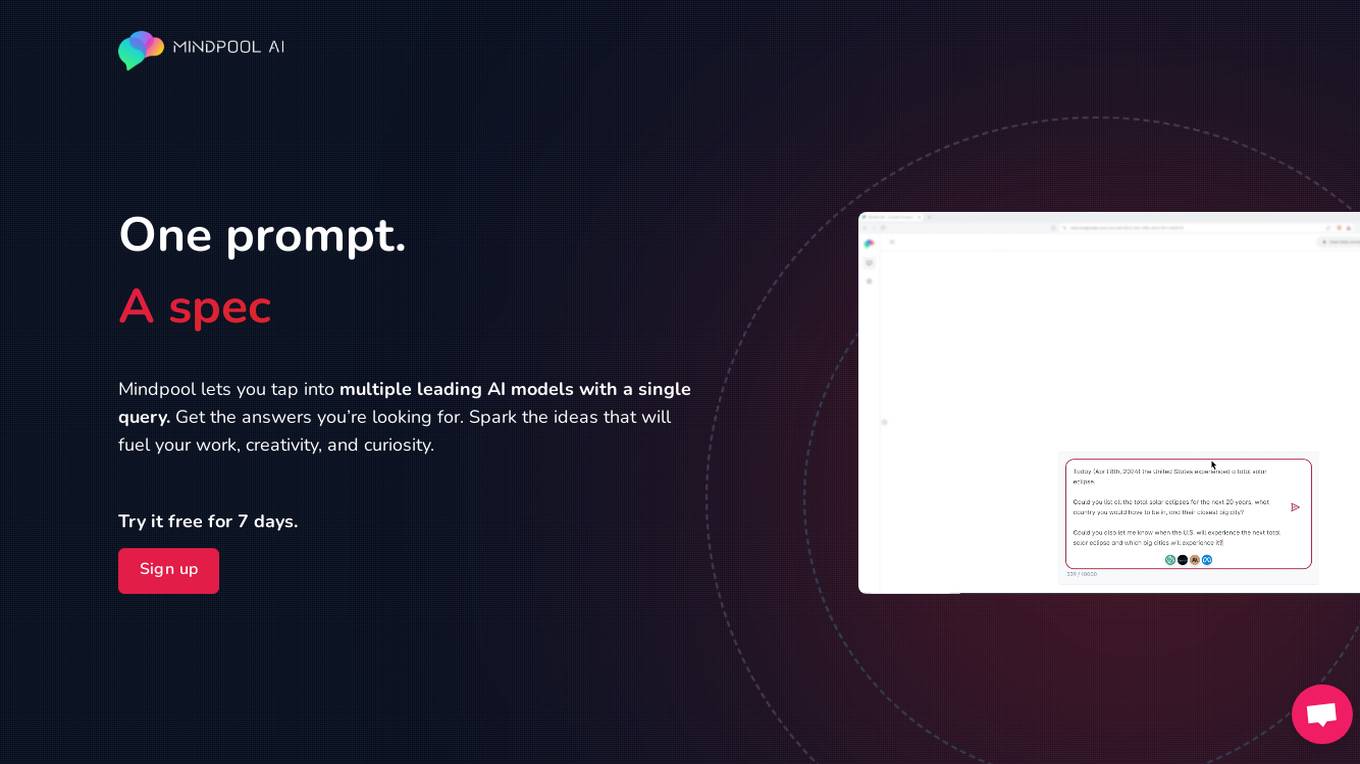
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.
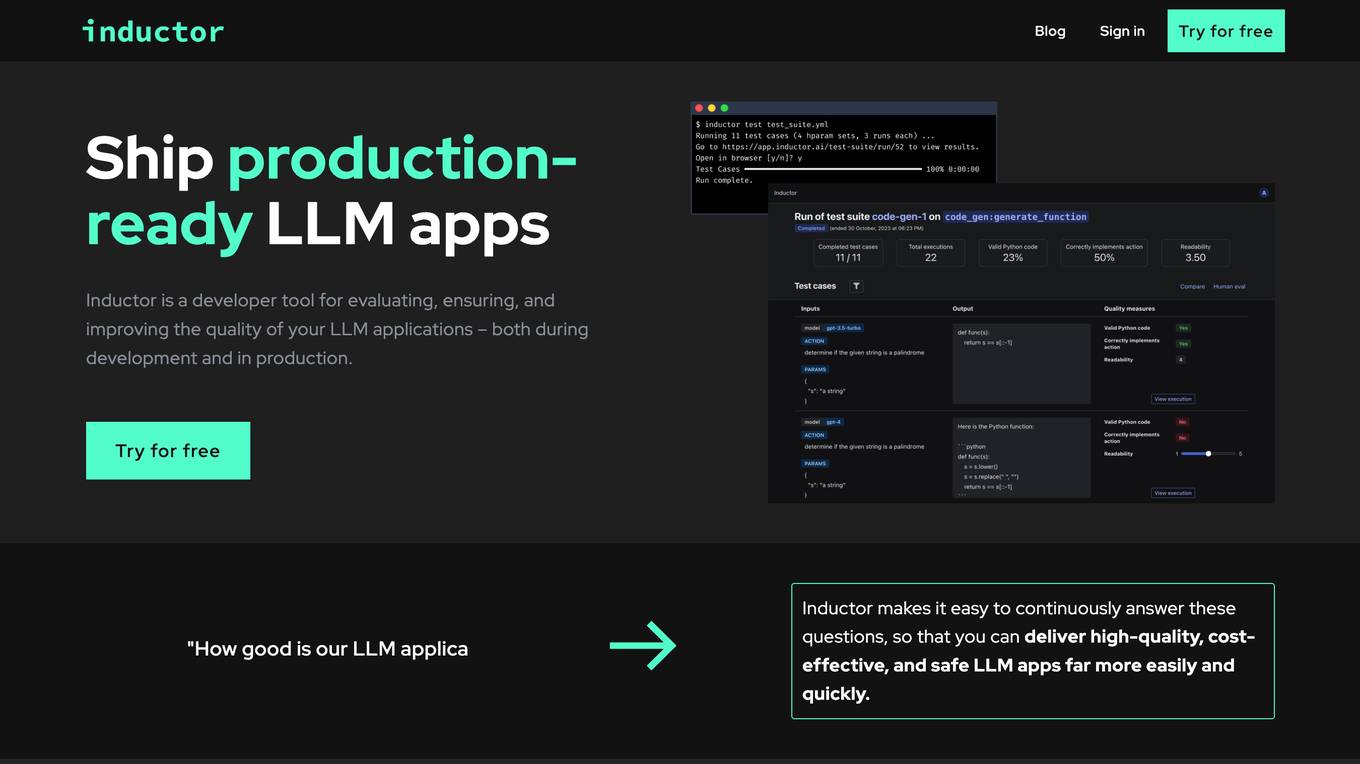
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Fritz AI
Fritz AI is an AI tool that scans and ranks all AI tools, apps, and websites based on a set of criteria to determine the best and most ethical options. They provide technical guides, reviews, and tutorials to help users get started with machine learning. Fritz AI focuses on ethics, functionality, user experience, and innovation when evaluating tools. Users can contribute tool suggestions and collaborate with the Fritz AI team. The platform also offers beginner-friendly guides, consulting services, and promotes ethical use of AI and machine learning technologies.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.
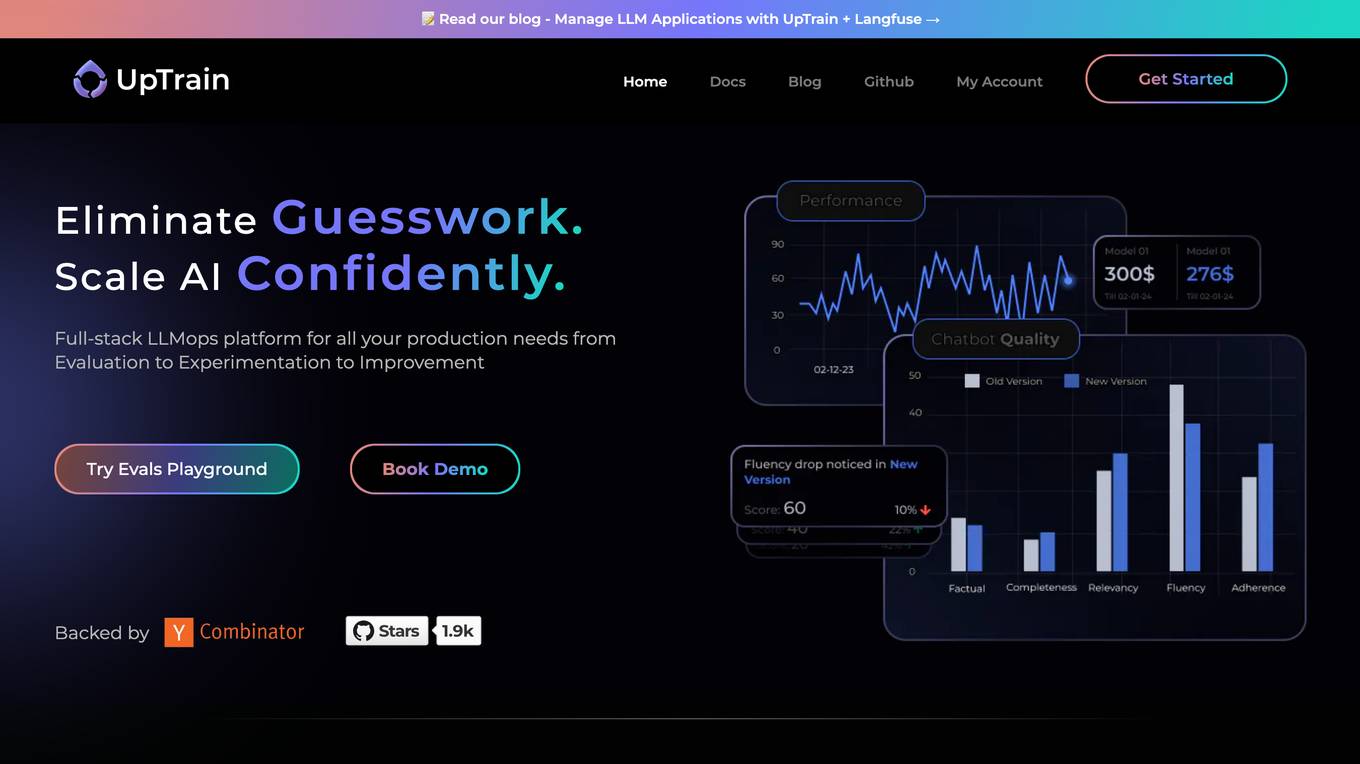
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
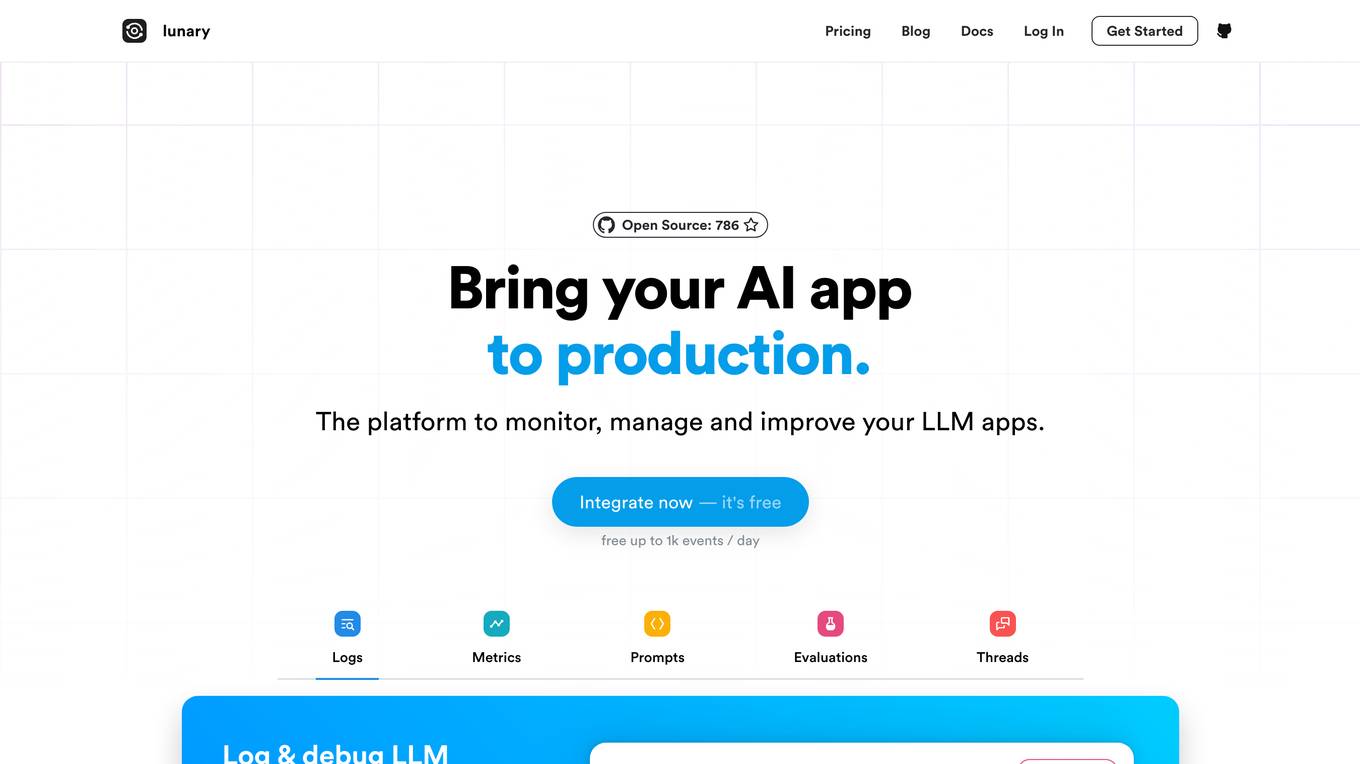
Lunary
Lunary is an AI developer platform designed to bring AI applications to production. It offers a comprehensive set of tools to manage, improve, and protect LLM apps. With features like Logs, Metrics, Prompts, Evaluations, and Threads, Lunary empowers users to monitor and optimize their AI agents effectively. The platform supports tasks such as tracing errors, labeling data for fine-tuning, optimizing costs, running benchmarks, and testing open-source models. Lunary also facilitates collaboration with non-technical teammates through features like A/B testing, versioning, and clean source-code management.
Vellum AI
Vellum AI is an AI platform that supports using Microsoft Azure hosted OpenAI models. It offers tools for prompt engineering, semantic search, prompt chaining, evaluations, and monitoring. Vellum enables users to build AI systems with features like workflow automation, document analysis, fine-tuning, Q&A over documents, intent classification, summarization, vector search, chatbots, blog generation, sentiment analysis, and more. The platform is backed by top VCs and founders of well-known companies, providing a complete solution for building LLM-powered applications.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.




CISO GPT
Specialized LLM in computer security, acting as a CISO with 20 years of experience, providing precise, data-driven technical responses to enhance organizational security.
NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence
EmotionPrompt(LLM→人間ver.)
EmotionPrompt手法に基づいて作成していますが、本来の理論とは反対に人間に対してLLMがPromptを投げます。本来の手法の詳細:https://ai-data-base.com/archives/58158
Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!

Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
SSLLMs Advisor
Helps you build logic security into your GPTs custom instructions. Documentation: https://github.com/infotrix/SSLLMs---Semantic-Secuirty-for-LLM-GPTs
Prompt For Me
🪄Prompt一键强化,快速、精准对齐需求,与AI对话更高效。 🧙♂️解锁LLM潜力,让ChatGPT、Claude更懂你,工作快人一步。 🧸你的AI对话伙伴,定制专属需求,轻松开启高品质对话体验
PyRefactor
Refactor python code. Python expert with proficiency in data science, machine learning (including LLM apps), and both OOP and functional programming.
![VitalsGPT [V0.0.2.2] Screenshot](/screenshots_gpts/g-cL1rJdm11.jpg)
VitalsGPT [V0.0.2.2]
Simple CustomGPT built on Vitals Inquiry Case in Malta, aimed to help journalists and citizens navigate the inquiry's large dataset in a neutral, informative fashion. Always cross-reference replies to actual data. Do not rely solely on this LLM for verification of facts.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
LLM-eval-survey
LLM-eval-survey is a collection of papers and resources related to evaluations on large language models. It includes a survey on the evaluation of large language models, covering various aspects such as natural language processing, robustness, ethics, biases, trustworthiness, social science, natural science, engineering, medical applications, agent applications, and other applications. The repository provides a comprehensive overview of different evaluation tasks and benchmarks for large language models.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.
Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

Awesome-LLM-RAG-Application
Awesome-LLM-RAG-Application is a repository that provides resources and information about applications based on Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) pattern. It includes a survey paper, GitHub repo, and guides on advanced RAG techniques. The repository covers various aspects of RAG, including academic papers, evaluation benchmarks, downstream tasks, tools, and technologies. It also explores different frameworks, preprocessing tools, routing mechanisms, evaluation frameworks, embeddings, security guardrails, prompting tools, SQL enhancements, LLM deployment, observability tools, and more. The repository aims to offer comprehensive knowledge on RAG for readers interested in exploring and implementing LLM-based systems and products.
LLM-Agents-Papers
A repository that lists papers related to Large Language Model (LLM) based agents. The repository covers various topics including survey, planning, feedback & reflection, memory mechanism, role playing, game playing, tool usage & human-agent interaction, benchmark & evaluation, environment & platform, agent framework, multi-agent system, and agent fine-tuning. It provides a comprehensive collection of research papers on LLM-based agents, exploring different aspects of AI agent architectures and applications.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.
Awesome-LLM-Psychometrics
This repository contains a collection of tools and resources for conducting psychometric analysis in the context of latent variable modeling. It includes scripts for data preprocessing, model estimation, and results interpretation. The tools provided here aim to assist researchers and practitioners in the field of psychology and related disciplines to analyze complex relationships among latent variables using advanced statistical techniques.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
LLM-PlayLab
LLM-PlayLab is a repository containing various projects related to LLM (Large Language Models) fine-tuning, generative AI, time-series forecasting, and crash courses. It includes projects for text generation, sentiment analysis, data analysis, chat assistants, image captioning, and more. The repository offers a wide range of tools and resources for exploring and implementing advanced AI techniques.